3D目标检测-BEVFormer、BEVDepth
很久没有更新博客了,近期一直在忙秋招相关的事情,抽空将暑期实习的3D目标检测资料进行总结归纳。由于篇幅过于繁杂,重点挑选基于纯视觉的BEV(鸟瞰图)的3D目标检测进行总结归纳,包括BEVFormer、BEVDepth。至于Focus3D、PETRv2、BEVFusion等,基于体素、点云和融合方案的3D目标检测有空可能会再做更新。
BEVFormer
BEVFormer有6个重复的encoder layers,每一层中,除了3个量身定制的设计(BEV queries, Spatial cross-attention, and Temporal self-attention),都是传统的transformers结构。在时间戳T上,多相机固像喂给backbone(比如ResNet-101)得到T时刻的特征图Ft;同时,保存前一个时间戳T-1的BEV特征Bt-1。在每—encoder layer,首先使用BEV queries Q,通过temporal self-attention去查询Bt-1,通过spatial cross-attention去查询Ft。前向传播后,当前encoder layer输出refined BEV特征,输入到next encoder layer。在6个堆叠的encoder计算后,生成当前时间戳T的统一BEV特征Bt,此后跟一个BEV检测器就可以满足3D目标检测的任务需求。
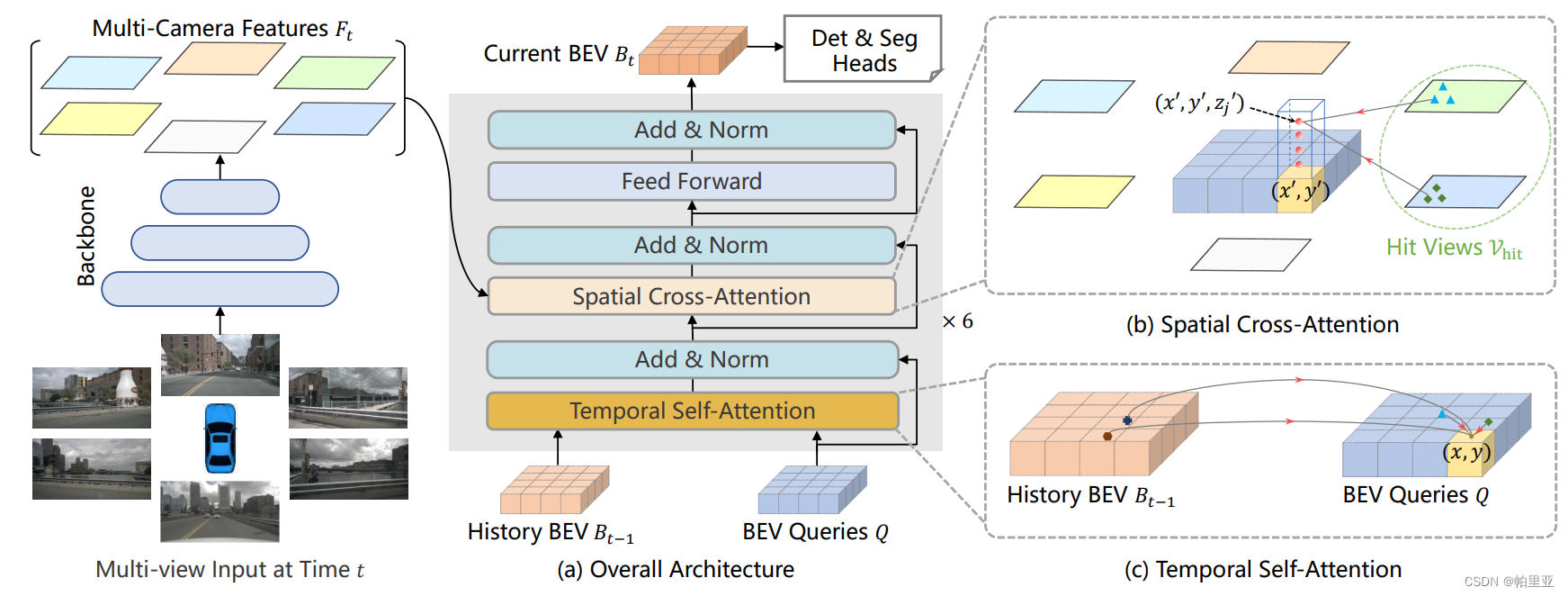
BEV Queries
这一步是生成一组网格型的可学习参数Q,其维度为(HxWxC)其中H和W是BEV平面的空间形状,当确定H和W则当前参数负责坐标点附近的网格区域,每个网格区域相当于真实世界的s米。BEV特征的中心默认是自身车辆。在输入BEVFormer之前,向中添加可学习的position embedding。
Spatial Cross-Attention
这一步根据BEV Queries,查询并聚合多相机图像的空间特征。首先将BEV平面上的每个query提升为柱状的query,从中采样3D参考点映射到2D视图。考虑到计算量,作者参考了Deformable Attention,令每个点之和相机的Rol交互,并且映射的2D参考点利用相机内外参计算获得对应的3D参考点并只对应部分视图。最终,将采样特征的加权和作为模块的输出,定义过程如下。 $$ SCA(Q_p,F_t) = \frac{1}{|V_{hit}|} \sum^{N_{ref}}{j=1} DeformAttn(Q_p,P(p,i,j),F^{i}{t}) $$ 其中i表示相机视图的索引,j表示2D参考点的索引,Nref表示对应BEV Query的所有3D参考点,Fit代表T时刻下第1个相机的图像特征。
Temporal Self-Attention
此外作者还想利用时序信息,设计了TSA根据BEV Query查询并整合历史BEV的时序特征。从历史BEV特征中提取时间信息,这有利于运动对象的速度估计和严重遮挡对象的检测,同时带来的计算开销可以忽略不计。首先依据ego-motion将T-1时刻的BEV特征对齐到Query,使同一个网格上的特征对应于同一个真实世界位置。考虑1个时间间隔内的运动将在真实世界中对应大量偏移,因此在TSA中对相邻时间的特征之间的联系进行建模。对于每个序列的第一个样本,TSA退化为无时间信息的自注意力,使用{Q, Q}代替{Q, Bt-1},将Q进行初始化。
$$ TSA(Q_p,(Q,B^{’}{t-1})) = \sum{V\in(Q,B^{’}_{t-1})} DeformAttn(Q_p,p,V) $$
3D object detection
论文中直接对2D检测器Deformable DETR进行了修改用于30目标检测,将生成的BEV特征作为检测器的输入,检测器除了定位外,还需要3D框大小和速度信息,并且使用L110ss监督回归。
总结
BEVFomer的优点是:1.使用了可变注意力机制,缩减了像素投影的范围,在指定的范围做自注意力,增强了网络特征提取的能力;2.利用了时序信息,对Q进行初始化,先将上一个时间的BEV特征与当前时间对齐,再利用可变注意力提取BEV特征,而非直接将时序信息拼接,大大提升了对遮挡物体的检测能力;3.利用了相机内外参选择了3D参考点,提高了网络对于深度信息的提取。
还可以提升改进的点有:1.选用更好的图像特征提取的主干网络,如:SwinTransformer、ConNext等;2、选择更加专业的检测头,现有检测头并没有进行BEV特征的再提取或融合,可以使用CenterPoint等Lidar方面的BEV检测头进行3D目标检测。
BEVDepth
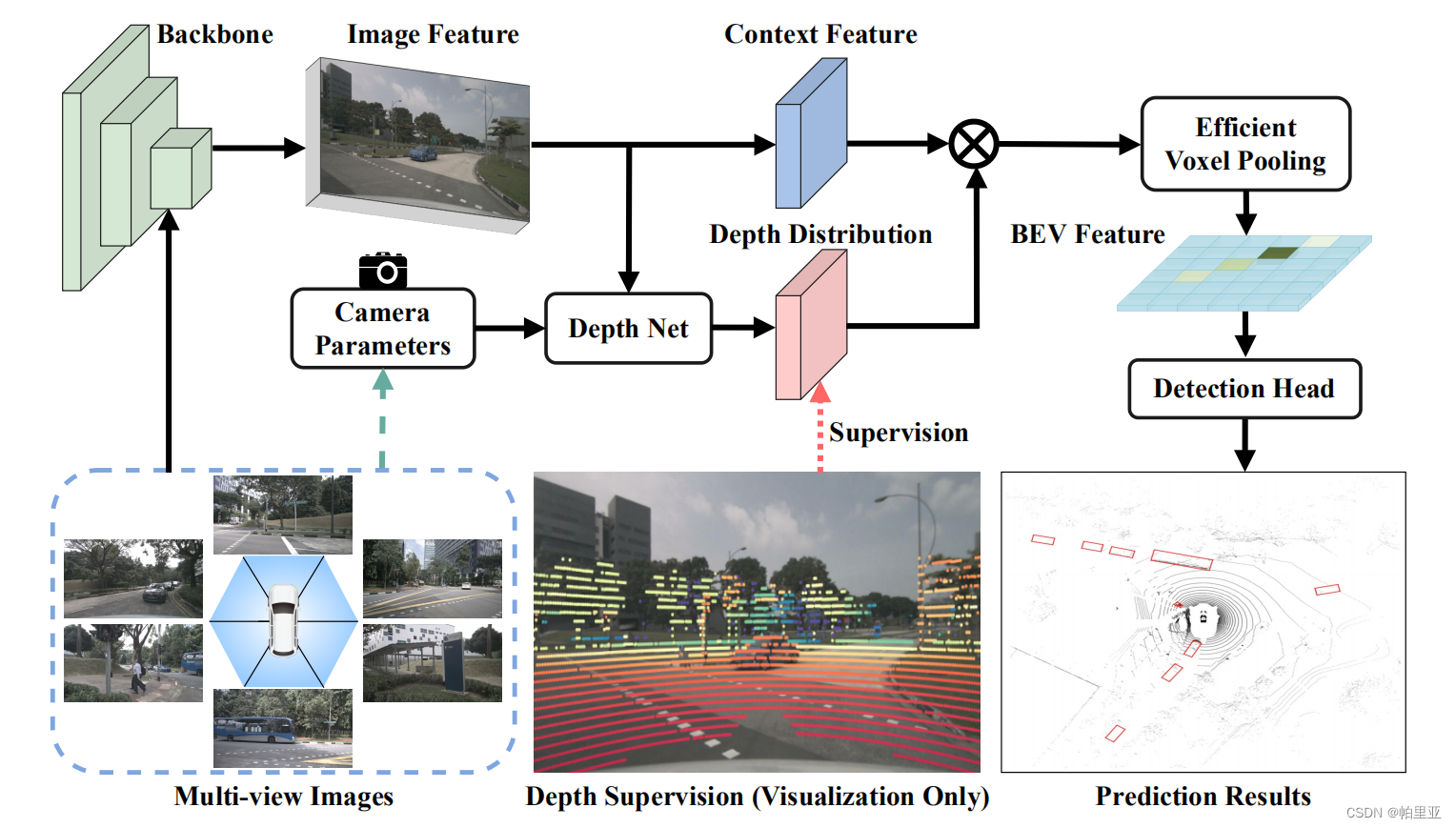
关于BEVDepth网络本身,原文写的非常的干脆:“Let us start from a vanilla BEVDepth, which simply replaces the segmentation head in LSS with CenterPoint head for 3D detection.",作者先是将CenterPoint网络的检测头对LSS网络的分割头进行替换,随后作者对显式深度监督、深度校正、相机感知深度预测和体素池化进行了添加或改进。
Lift, Splat, Shoot
LSS是英伟达针对BEV任务提出的一种端到端的方法,将二维图像特征生成3D特征(对应Lift操作),然后把3D特征“拍扁”得到BEV特征图(对应Splat操作),最终在BEV特征图上进行相关任务操作(对应Shoot操作)。在BEVDepth中参考借鉴了Lift-Splat模型,Lift操作为每个像素点生成一堆离散的深度值,在模型训练的时候,由网络自己选择合适的深度。如相机视锥中一根射线上设置了10个可选深度值,第三个深度下特征最为显著,因此该位置的深度值为第三个。得到了像素的2D像素坐标以及深度值后,Splat操作利用相机的内参以及外参,即可计算得出像素对应的在车身坐标系中的3D坐标,最后将3D坐标投影在同一张俯视图中获得BEV特征。
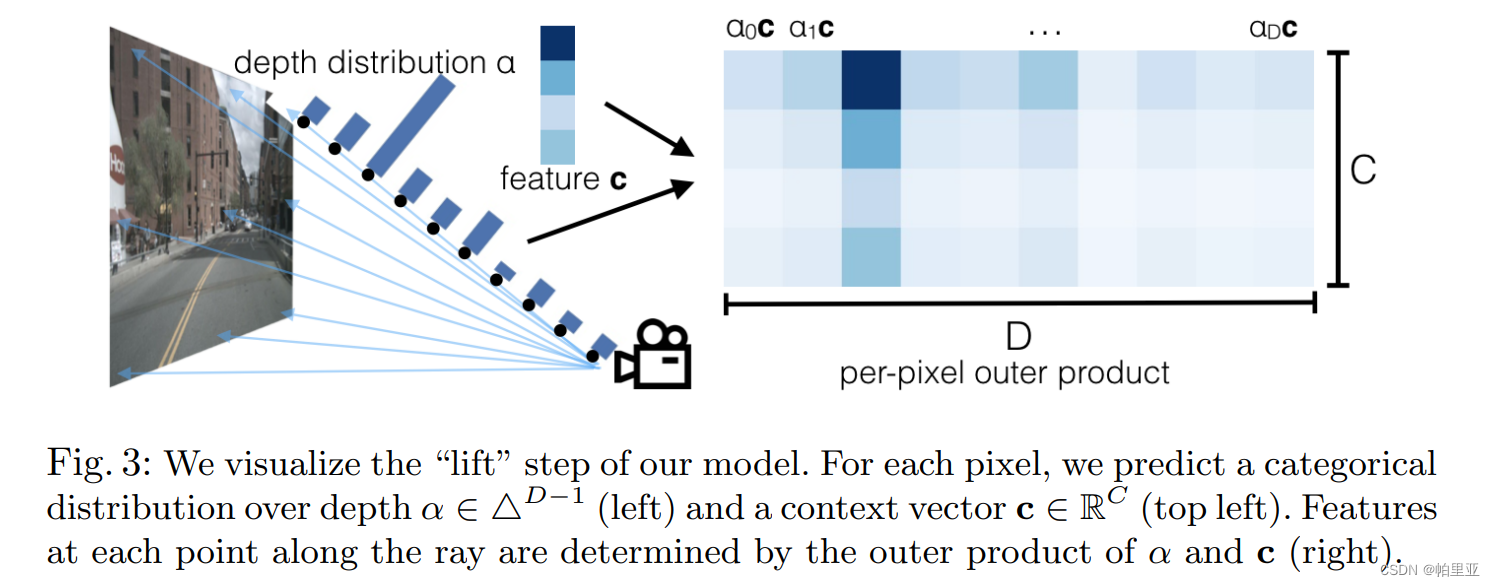
显式深度监督
作者认为原有单独的检测损失监督并不能很好的监督深度预测模块,因此提出了显式深度监督的方法(DepthNet),论文的做法是利用点云数据派生的Dgt去监督深度预测的Dpred。首先,将相机获取的图像根据外参对齐到车辆自身坐标系下,并利用相机内参获取图像上各个像素点的深度值;随后使用真实的点云深度数据与计算得到的深度数据做对齐,具体的操作为min-pooling和one-hot,从而获得假定的深度真值;最后简单使用交叉熵对深度预测进行监督和回归。
深度校正
在车辆行驶的过程中,相机的外参并不能保持绝对的稳定,而当DepthNet的感受野受到约束时,根据内外参计算图像深度得到的假定真值和真实的深度信息就会有较大的偏差。因此作者引入了多层残差网络和可变形卷积加入到深度预测模块的末端,以消除上述问题所带来的假定真值的偏差。

相机感知深度预测
众所周知,通过相机内外参数可以将2D图像映射到3D坐标系下,因此为了进一步提升网络对深度信息的预测,作者选择将相机的内外参也输入到神经网络中。首先将内外参展平合并送入MLP,使得相机参数的维度与特征图对齐;随后和SE模块类似利用相机参数特征对原有的特征图进行权重再分配;最后将获得的特征输入到先前介绍的深度矫正中,从而获得预测的深度信息并由先前假定的真值进行监督。得益于LSS的解耦性,深度预测模块与检测头是互相独立的,因此不需要更改回归目标,使得网络具有更大的可扩展性。
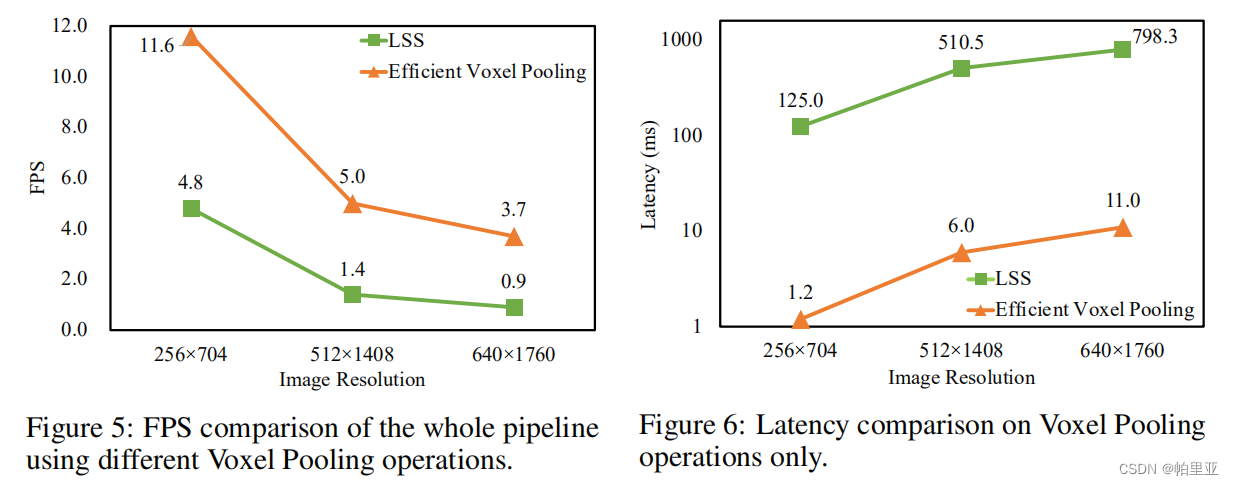
体素池化
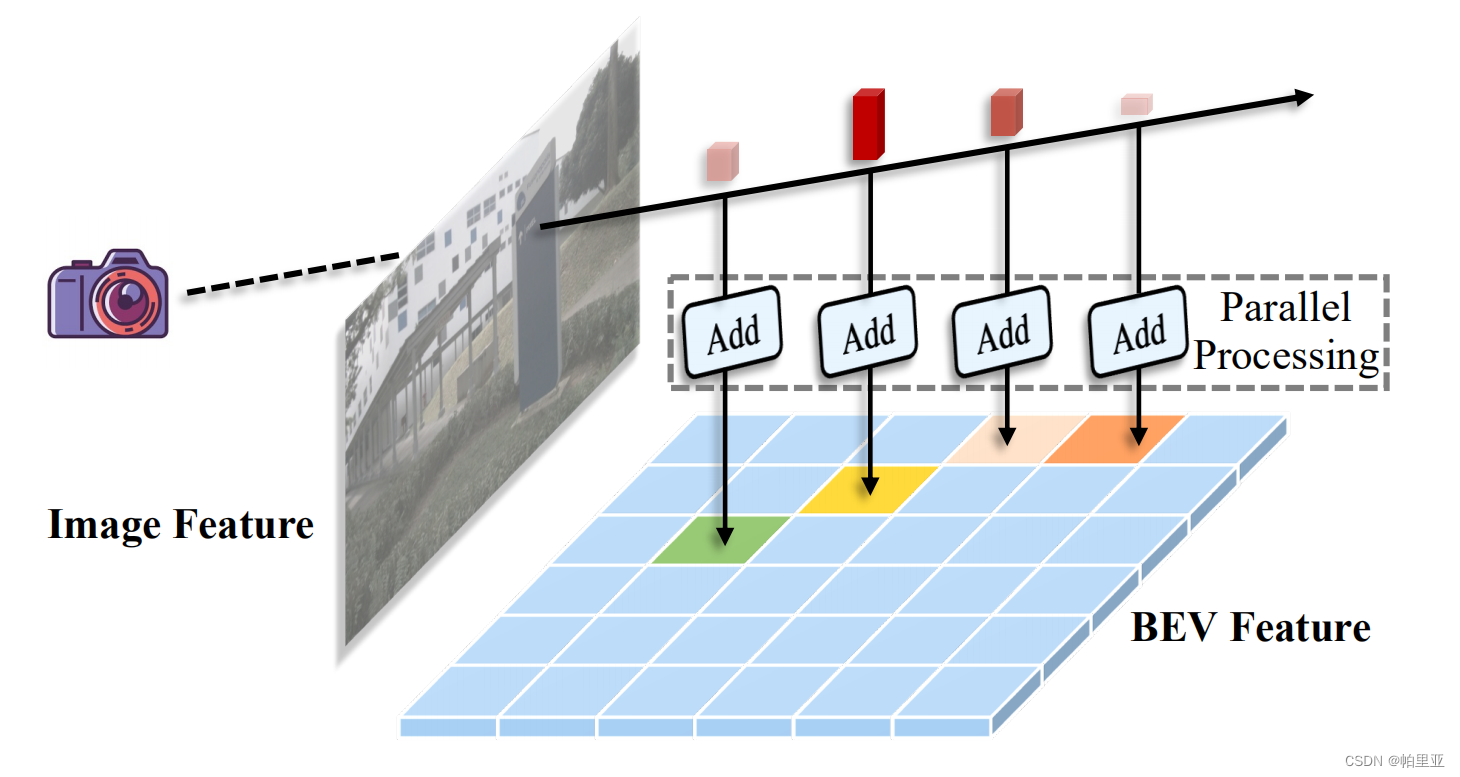
CenterPoint的检测头是一个BEV检测器,而体素池化是为了将先前获得的3D特征聚合成一个BEV特征。通常是基于车体坐标系将周围的空间划分为几个均匀分布的网格,然后将落入同一网格的3D特征相加形成相应的BEV特征。对应LSS的Splat模块利用累计求和的技巧,先对落入BEV网格的所有的特征进行累计求和,然后减去特征边界部分的累计求和。作者认为原有的算法存在较多的重复计算,且计算效率低下,因此作者提出了一种高效的体素池化方法。主要想法是为每个体特征分配一个CUDA线程,用于将该特征添加到其相应的BEV网格中。
CenterPoint
CenterPoint是一个基于雷达的3D目标检测网络,由于其主干网络输出的是BEV特征图,且该网络的检测头在多种基于BEV的检测任务中效果较好,因此BEVDepth同样选择了直接使用CenterPoint的检测头作为任务头。完整的CenterPoint检测头分为两个阶段:第一阶段网络的输出为基于类的Heatmap;细化的子体素位置、目标的大小、转角和速度;第二阶段网络根据第一阶段的检测框信息和特征图信息,从预测边框的每个面的三维中心提取一个点特征。对于每个点,使用双线性插值从主干map-views输出M中提取一个特征,并将点特征输入全连接网络MLP对结果进行细化。由于二阶段主要简化并加速了之前的基于PointNet的特征提取器和RolAlign操作的两阶段3D检测器,并不适用于其它BEV特征提取器,所以在BEVDepth中仅仅使用了CenterPoint的一阶段作为训练和推理的检测头。
Heatmap的生成方式与CenterNet类似:对于任意尺寸为WxHx3的图像,会生成一个尺寸为WIRxH/RxK的Heatmap,其中K是检测的类别数,R是缩放比例。Heatmap中的元素的取值为0或1,其中若热力图该点为1,则图像中该点是一个检测框的中心,若为0,则该点在图像中为背景。
Centerpont与CenterNet区别是:由于三维空间中目标分布离散且三维目标不像图像中的目标一样近大远小,如果按照CenterNet的方式生成Heatmap,那么Healmap中将大部分都是背景,作者的解决方法是设置高斯半径公式为a= max((w),r),其中1为最小高斯半径值,f为 CenterNet的高斯半径求解方法,及生成二维高斯圆作为目标。

除了目标物的中心点以外,还需要回归子体素位置细化、中心点离地高度、3D框大小、方向这些性质。子体素位置细化可以减少来自骨干网络的体素化和跨步的量化误差;离地高度可以帮助在3D中定位目标,并添加了地图视图投影删除的丢失的高度信息;大小预测和方向预测则将检测框完全定义,其中方向预测是将yaw角的正弦和余弦作为连续回归目标。一阶段的最后为了通过时间跟踪目标,模型学习预测每个检测到的目标的二维速度估计,作为额外的回归输出。具体的预测方法需要时态点云序列,将先前帧中的点转换并合并到当前帧中,并预测当前帧和过去帧之间的目标位置差异,通过时间差(速度)进行归一化。 与其他回归目标一样,速度估计也使用当前时间步的地面实况对象位置的L1损失进行监督。
总结
BEVDepth作为现在nuScenes3D目标检测的SOTA方案,我认为它的优点是:1.端到端的3D目标检测任务,并没有附加别的BEV任务头,大大增强了回归的专一性;2.利用点云数据和相机内外参对深度预测进行了增强,并且将相机内外参也作为网络的输入进行深度信息的提取;3.增加了深度信息的自监督学习,使得网络对3维空间的信息有更好的提取效果;4.不同于BEVFormer和PETR√2使用Transfomer生成BEV特征,BEVDepth采用的是Lift-Splat方法,更接近Lidar的处理方式,使得BEVDepth拥有更好的性能。
不过BEVDepth并没有使用时序信息更新BEV特征,且直接使用了CenterPoint的检测头并没有设计更好的检测头,2D图像特征提取的主干网络也选择了残差网络,所以仍然有很多可以改进升级的地方。